一致性哈希算法
一致性哈希算法英文Consistent Hashing,由麻省理工学院在1997年提出的一种分布式哈希(DHT)实现算法。
设计目标是为了解决因特网中的热点问题,初衷和CARP十分类似。
一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得分布式哈希可以在P2P环境中真正得到应用。
在分布式集群中,对机器的添加、删除,或者机器故障后自动脱离集群操作,是分布式集群管理最基本的功能。
如果采用常用的hash(object)%N算法,那么在有机器添加或者删除后,很多原有的数据就无法找到了。
接下来主要讲解一致性哈希算法的设计实现。
1 环形Hash空间
首先,按照常用的hash算法,将对应的key哈希到一个具有2^32次方个桶的空间中。
即0~(2^32)-1的数字空间中。
将这些数字头尾相连,想象成一个闭合的环形。
如下图:
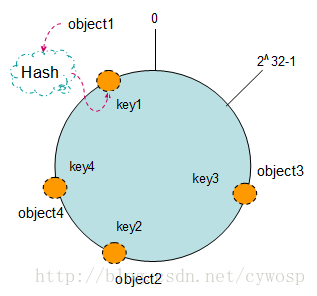
2 放入数据
然后,把数据通过一定的hash算法处理后映射到环上。
例如,现在我们将object1、object2、object3、object4四个对象,
通过特定的Hash函数计算出对应的key值,
Hash(object1) = key1; Hash(object2) = key2; Hash(object3) = key3; Hash(object4) = key4;
然后散列到Hash环上,如下图:
3 放入机器
再将机器通过hash算法映射到同一个环上。
在分布式集群中加入新的机器,原理是:通过使用与对象存储一样的Hash算法将机器也映射到环中。
一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值。
因为与对象存储使用同样的Hash算法,所以插入点与对象不会重叠。
然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
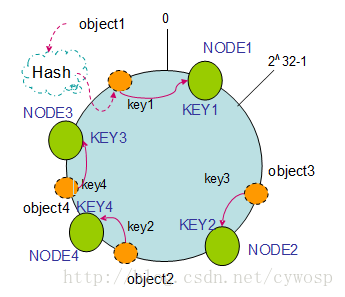
假设现在有NODE1、NODE2、NODE3三台机器,通过Hash算法得到对应的KEY值,
Hash(NODE1) = KEY1; Hash(NODE2) = KEY2; Hash(NODE3) = KEY3;
映射到环中,示意图如下:
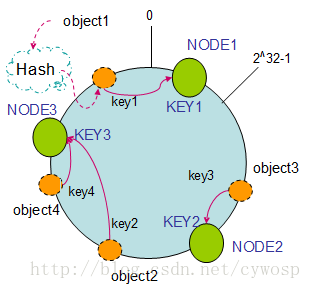
通过上图可以看出,对象与机器处于同一哈希空间中。
然后按顺时针转动对象存储到最近的机器中。
这样,object1存储到了NODE1中,
object3存储到了NODE2中,
object2、object4存储到了NODE3中。
在这样的部署环境中,hash环是不会变更的。
因此,通过算出对象的hash值,就能快速的定位到对应的机器中,找到对象真正的存储位置。
4 机器增删
hash求余算法存在的问题,就是在有机器的添加或者删除之后,会照成大量的对象存储位置失效。
那一致性哈希算法是如何处理的呢。
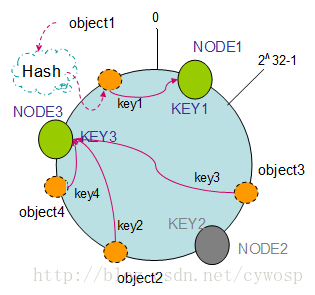
4.1 机器的删除
以上面的分布为例,如果NODE2出现故障被删除,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中。
这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动。
如下图:
4.2 机器的添加
如果往集群中添加一个新的节点NODE4,通过对应的哈希算法得到KEY4,并映射到环中。
如下图:
通过按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它对象还保持这原有的存储位置。
通过对节点的添加和删除的分析,一致性哈希算法避免了大量数据迁移,减小了服务器的的压力,对分布式集群来说是非常合适的,
5 平衡性
hash算法是不保证平衡的,如上面只部署了NODE1和NODE3的情况(NODE2被删除的图)。
object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中。
这样就照成了非常不平衡的状态。
在一致性哈希算法中,为了尽可能的满足平衡性,其引入了虚拟节点(机器)。
虚拟节点是实际节点在 hash 空间的复制品,在 hash 空间中以hash值排列。
一个实际节点对应了若干个虚拟节点,这个对应个数也成为“复制个数”。
以上面只部署了NODE1和NODE3的情况为例,原本对象在机器上的分布很不均衡。
现在我们以2个副本(复制个数)为例,这样整个hash环中就存在了4个虚拟节点,最后对象映射的关系图如下:
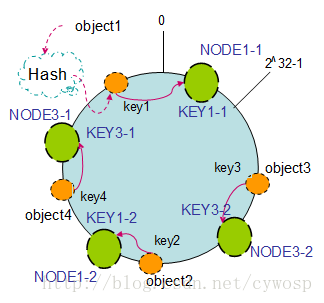
根据上图可知对象的映射关系:
object1 -> NODE1-1 object2 -> NODE1-2 object3 -> NODE3-2 object4 -> NODE3-1
通过虚拟节点的引入,对象的分布就比较均衡了。
那么在实际操作中,正真的对象查询是如何工作的呢?
对象从hash到虚拟节点到实际节点的转换如下图:
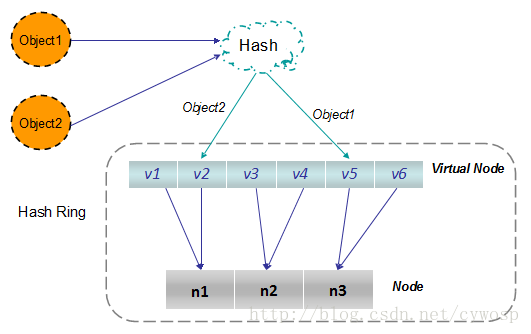
虚拟节点的hash计算可以采用对应节点的IP地址加数字后缀的方式。
例如假设NODE1的IP地址为192.168.1.100。引入虚拟节点前,计算 cache A 的 hash 值:
Hash(“192.168.1.100”);
引入虚拟节点后,计算虚拟节点NODE1-1和NODE1-2的hash值:
Hash(“192.168.1.100#1”); // NODE1-1 Hash(“192.168.1.100#2”); // NODE1-2
参考资料:
兴致勃勃的进来,一脸懵比的出去