Spring Boot 集成 GraphQL 分页功能
经验上,我们会这样分页:传入页码数page和size,后台根据page和size计算offset和limit,从数据库中拿到并返回数据集。这种方式可以随意跳页,但是在数据量大的时候,会有性能问题。
在GraphQL中的分页与offset方式有一定差别,我们的参数不再是page,而是上一次查询的最后一个游标(简单可以理解为最后一条数据的id),每次查询都是在这个游标的基础上,在大数据的情况下可以高效利用索引,提高性能,但是缺点就是不能随意跳页。
以下我们详细说明分页类型。
1 分页方式
1.1 Offset 方式
以前自己在学习写网页时,关于如何实践分页这件事,只知道使用OFFSET + LIMIT的方式来完成,但那时候对于效能并没有什么很好的概念,后来才知道OFFSET + LIMIT在资料量大的时候会非常地缓慢,也会造成资料库的极大负担。
这个原因主要是当资料量大时,你所设定的OFFSET 实际上资料库还是会一笔一笔的去读取,直到读到你所设定的「偏移量」,但前面所有读取的根本就用不到,这些都造成了计算的浪费。以下是一个范例:
SELECT * FROM artists WHERE country = 'USA' ORDER BY id DESC LIMIT 5 OFFSET 5;
假设我有一个artists的table,我需要查询艺人的country是USA的,每一次只搜寻5笔(LIMIT 5)并根据id作为排序,而目前在第二页(OFFSET 5):
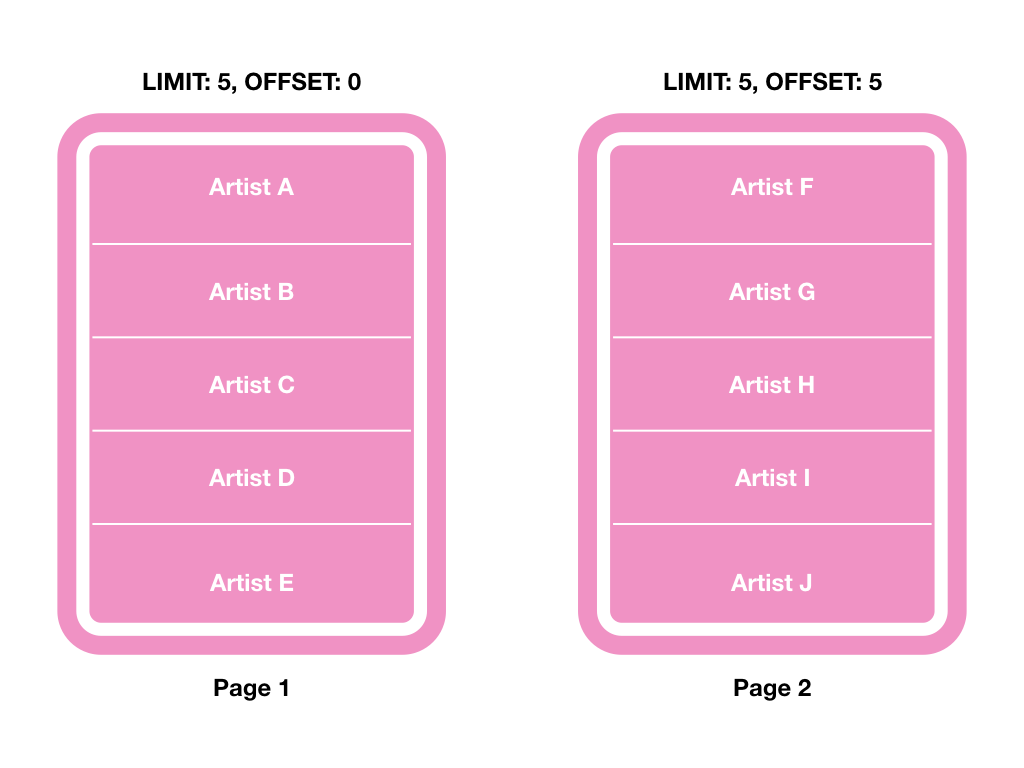
如上图,假设B使用者目前位置是第2页,当A使用者同时在某处新增1位艺人时,B使用者有可会在下一页(第3页)又看到重复的艺人资料Artist J,这是因为新增的资料会被排序到更前面(可能会在第一页),所以会发现OFFSET + LIMIT不能有效地处理这类的情况。
当然offsets 的方式还是有它的优点存在,例如:计算资料的总数量、目前页数,或者是可以跳到指定的页数。
1.2 Cursor 方式
基于Cursor的分页(Cursor-based pagination)是透过指定明确的起始点(Pointer)来回传资料,这个方法解决了OFFSET方式的一些缺点,但是这需要一些取舍:
- Cursor必须基于一个「唯一」或是「有序」的栏位(例如:
id或是created_at) - 它没有「总和」和「页数」的概念
在资料表中,这个「唯一」不一定是指单一的栏位,也可以是两个栏位作为一个唯一。
将先前的范例改写为使用cursor-based的分页方式,以id 作为cursor来取得资料,以下是取得第1页的资料:
SELECT * FROM artists WHERE country = 'USA' ORDER BY id DESC LIMIT 5 + 1;
应该注意到了在LIMIT 的部分有一点不一样,先前的范例中我们一页想要取得5 笔资料,但为什么要加1 呢?
💡 主要为了确定是否还有上(下)一页的资料,但这一笔「多取得」的资料并不会回传给client 端
当处理完资料之后,这时候server 会回传类似如下的response 给client:
{
"data" : "[...]" ,
"cursor" : "bd66b4d5c168b85676f38eeb9a4b0678"
}
如上所述,cursor-based 它没有「总和」和「页数」的概念,因为每一次回来都是一个资料的集合。
Client在收到response后,就可以在每一次的request中,藉由设定cursor和limit来继续取得资料:
SELECT * FROM artists WHERE country = 'USA' AND id <= $cursor ORDER BY id DESC LIMIT $limit + 1;
与offsets 的方式做比较,可以发现cursors 解决了offsets 的一些缺点:
- 由cursors 可以很明确直接的指定资料的范围从哪开始;相较于offsets 需要读取每一行直到设定的偏移量,这在资料量大时可以减少database 的负荷。
- 对于database可能会被频繁写入资料的时候,offsets可能会因为资料的新增或删除造成资料的排序错误。
利用下图作为一个情境,来解释cursors 是如何确保资料正确的排序:
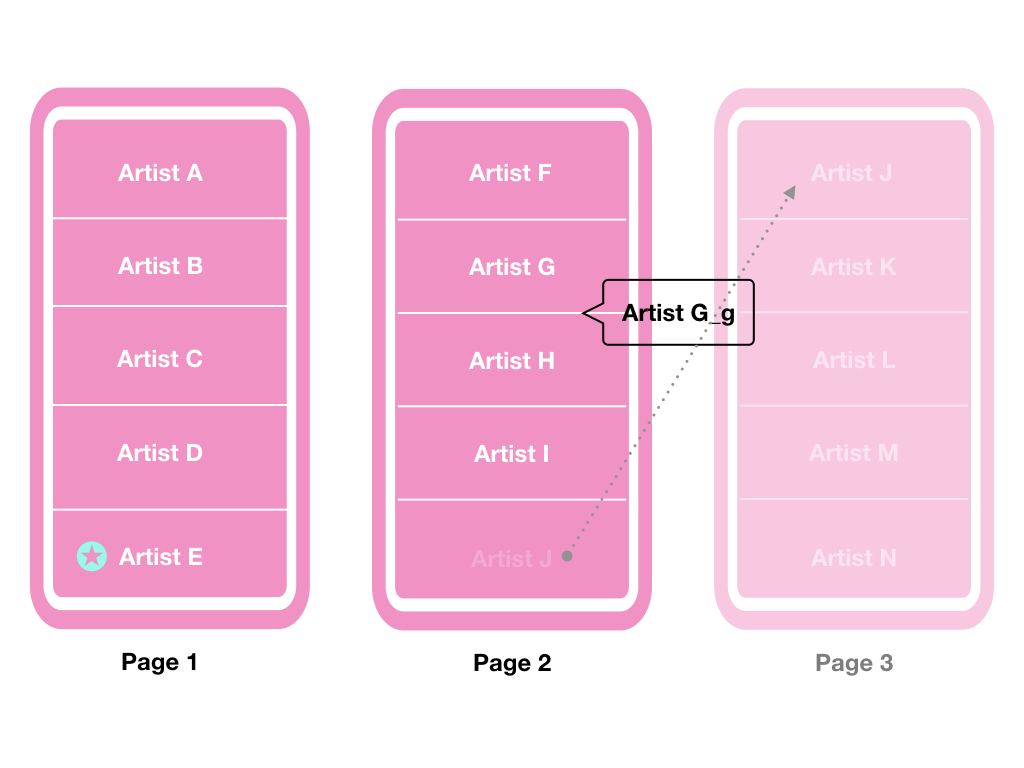
例如某A使用者刚进入到页面(Page 1),他点击了下一页的按钮,这时候会发出一个request透过Artist E的cursor去取得下一页的资料,与此同时,某B使用者在别处新增了一个Artist G_g,而它的id刚好位于Artist G以及Artist H之间,这时候从Page 1往下一页拿5笔资料时,的排序应该会是:
Artist F | Artist G | Artist G_g | Artist H | Artist I
而Artist J则会因为新增的Artist G_g的关系,将会出现在第3页。
2 什么是Cursor Connections ?
根据GraphQL官方文件,可以得知在GraphQL中实践分页会透过cursor-based的方式,通常会遵循Relay Cursor Connections spec来定义GraphQL schema,以下几个是必要的栏位:
Connection Type
- edges
- pageInfo
Edge Type
- node
- cursor
PageInfo
- hasNextPage
- hasPreviousPage
我用一个Artist 的schema 来作为一个简单的范例:
type Artist {
id : String !
name : String !
avatar : String
createdAt : DateTime !
updatedAt : DateTime !
}
type ArtistsConnection {
edges : [ ArtistEdge ! ] !
pageInfo : PageInfo !
}
type ArtistEdge {
node : Artist !
cursor : String !
}
type PageInfo {
hasNextPage : Boolean !
hasPreviousPage : Boolean !
}
每一个分页都是一个Connection,Connection底下会有许多的Edge,而每个Edge都会有一个Node,而这个Node也就是我们实际的资料,在这里指的是Artist,而cursor则是用来辨识Edge,通常会将cursor做encode,而PageInfo则是每一页的信息。
3 GitHub GraphQL API 进行测试
以往在实践分页,都会在网址上设计query string(例如:https://foobar.com/?page=1)来方便的换页,只要修改page后的数字就可以跳到指定的页数。如前面所提到,这个实践通常是透过offsets的方式,所以你可以让你随心所欲换到想要的页数,这里推荐一下Laravel Pagination的文件,有兴趣可以了解一下。
在GraphQL中,你不一定会将参数显示在网址上,因为所有的参数很有可能都透过GraphQL的query一起被送出去(使用POST方式),不过还是要看routing是怎么设计的,也许也有些参数需要在网址上,这一切都要看需求而去设计,没有所谓的正确。
GitHub提供一个GraphQL API Explorer,只要你有GitHub帐号,登入授权后就可以使用。例如你可以使用curl取得GitHub的个人资料:
$ curl \
-X POST \
-H "Content-Type: application/json" \
-H "Authorization: bearer GithubAccessToken" \
--data '{ "query": "{ viewer { name } " }' \
https://api.github.com/graphql
-X代表的是http 的method-H代表的是http 的header--data代表的是要传送的资料
下图则是GraphiQL的互动介面:
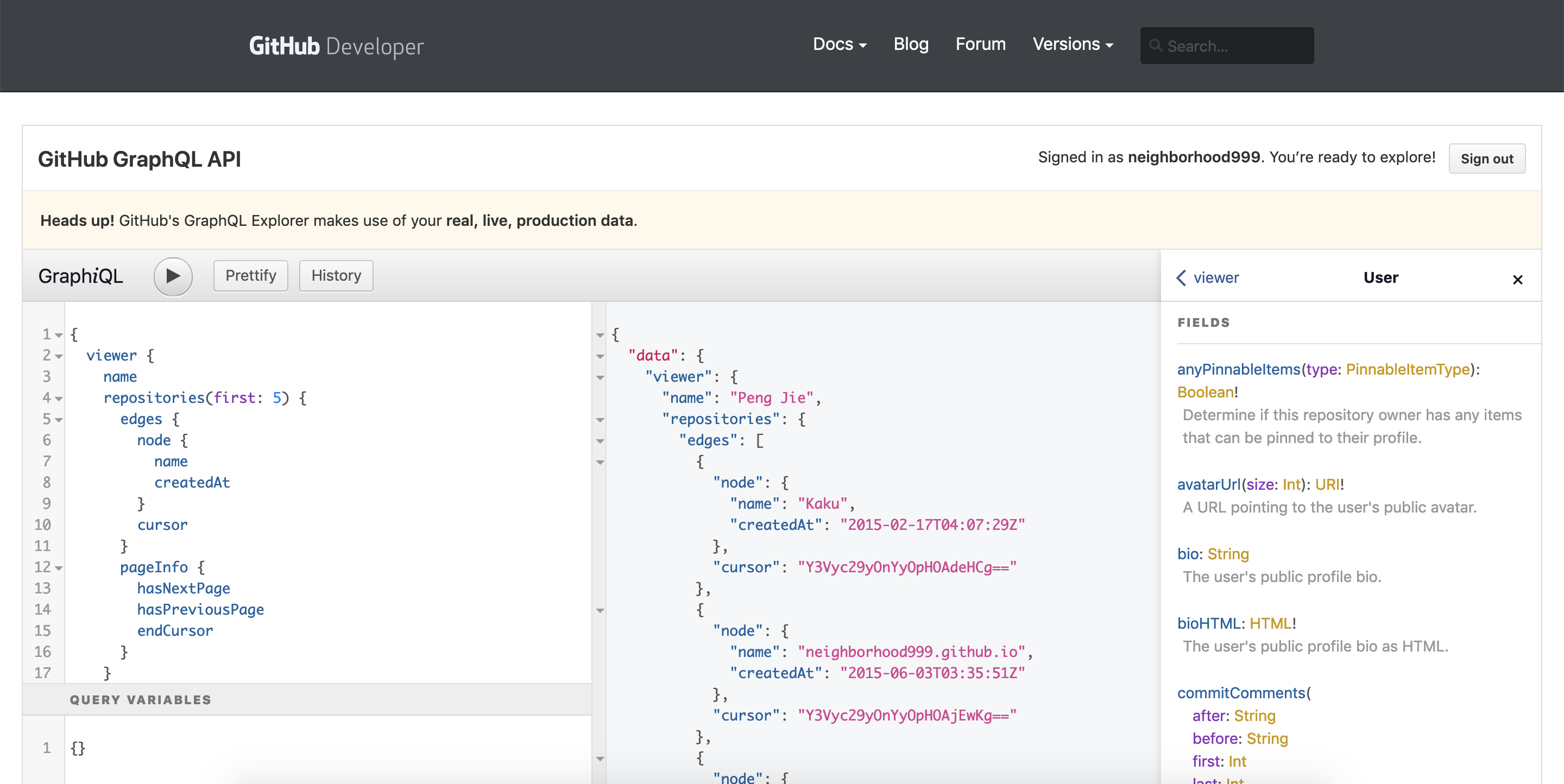
透过GraphiQL可以知道有哪些栏位是可以被查询到的,本篇文章以Pagination(分页)作为主题,所以选了repositories来作为说明的范例,并且简单分析GitHub如何实践GraphQL Pagination。
首先,透过Document Exploer从viewer开始看起,你会发现viewer下有许多栏位,请往下卷动找到repositories的栏位:
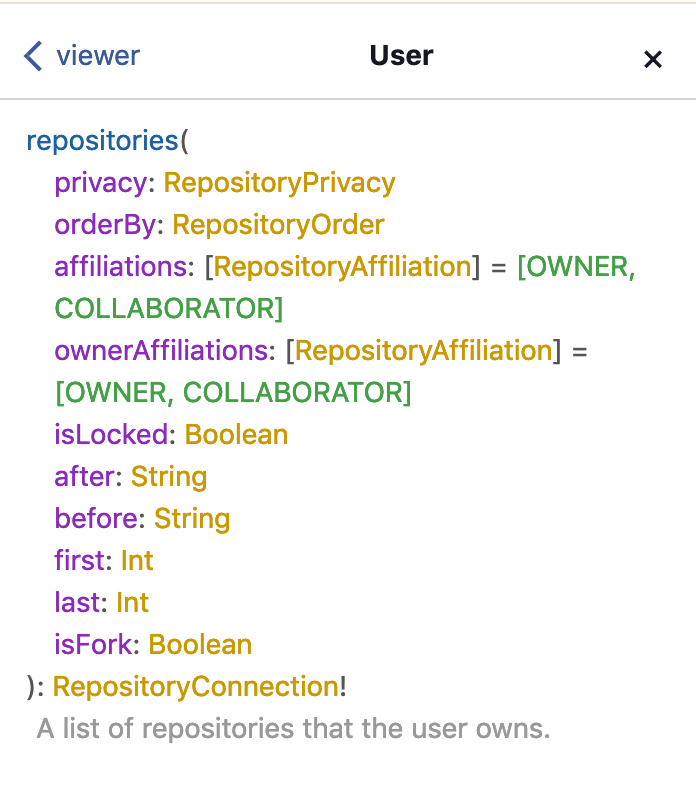
可以看到repositories提供了许多参数让你可以输入,而回传的type是RepositoryConnection,这符合了上方我们所提到的Connection的schema定义,点进去后可以看到:
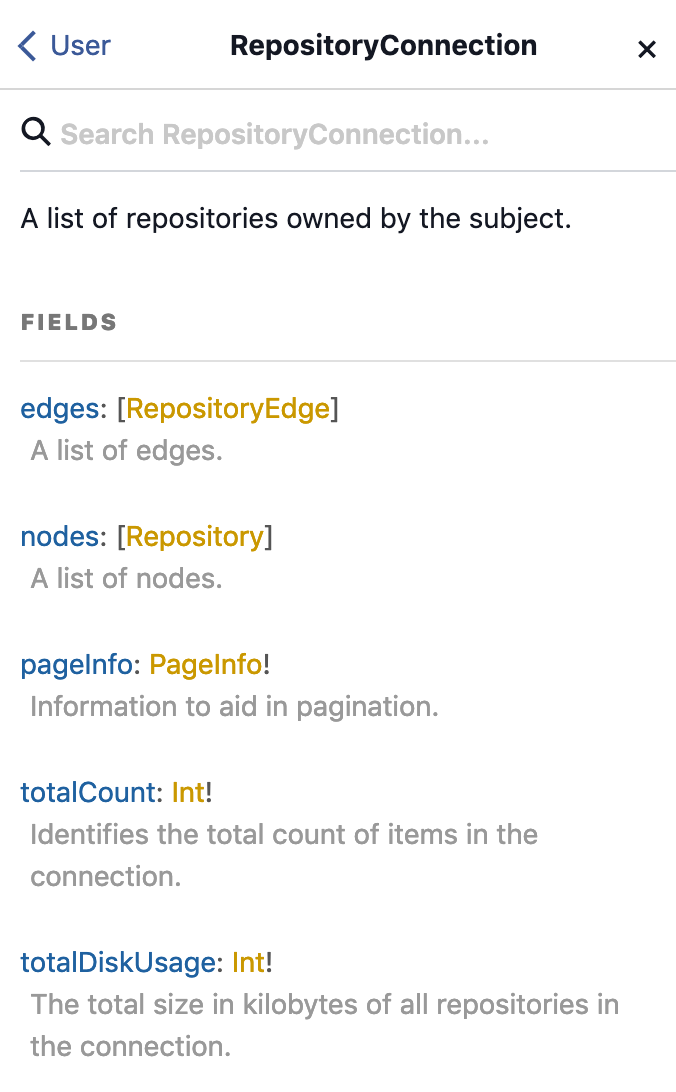
眼尖的你不知道有没有注意到edges它并不是required?这是不是跟上面所提到的规范好像不太一样?实际在上实践的时候这些都是有弹性的,不一定要完整的遵循规范,所以像GitHub在实践这里就采用了不同的方式。
除了上述规范提到的edges和pageInfo是必须的之外,其余的栏位可以根据需求自行增加,如上图可以看到还有其他像是totalCount等其他栏位。
在GraphQL Pagination中,会透过first或last来设定要取得的资料笔数,以GitHub GraphQL API作为范例:
{
viewer {
name
repositories ( first : 3 ) {
edges {
node {
name
createdAt
}
cursor
}
pageInfo {
hasNextPage
hasPreviousPage
endCursor
}
}
}
}
执行查询后,可以拿回如下的资料:
{
"data" : {
"viewer" : {
"name" : "Peng Jie" ,
"repositories" : {
"edges" : [
{
"node" : {
"name" : "Kaku" ,
"createdAt" : "2015-02-17T04:07:29Z"
} ,
"cursor" : "Y3Vyc29yOnYyOpHOAdeHCg=="
} ,
{
"node" : {
"name" : "neighborhood999.github.io" ,
"createdAt" : "2015-06-03T03:35:51Z"
} ,
"cursor" : "Y3Vyc29yOnYyOpHOAjEwKg=="
} ,
{
"node" : {
"name" : "redux" ,
"createdAt" : "2015-07-14T15:57:27Z"
} ,
"cursor" : "Y3Vyc29yOnYyOpHOAlRj9g=="
}
] ,
"pageInfo" : {
"hasNextPage" : true ,
"hasPreviousPage" : false ,
"endCursor" : "Y3Vyc29yOnYyOpHOAlRj9g=="
}
}
}
}
}
请仔细观察资料的排序,是按照时间由旧至新,所以在这边可以合理推测repositories的first实践可能是:
SELECT * FROM artists ORDER BY created_at ASCLIMIT $first ;
💡
$first用来代表参数的意思。
反之如果使用last作为参数资料的排序则是按照时间由新至旧:
SELECT * FROM artists ORDER BY created_at DESC LIMIT $last;
在实践上对于资料的排序可以根据自己的需求做调整,例如你可能希望是由新到旧,那first的排序就应该是DESC,而last的排序则是ASC。
另外,GitHub GraphQL API也提供了orderBy参数让你可以自行调整资料的排序方式,这些在你实践时都可以考虑提供这些参数让资料排序可以更加地弹性。
4 Spring Boot 实现 GraphQL 分页
4.1 安装 graphql 依赖
安装过程请参考另外一篇文章,简单4步就可以了,《Spring Boot 集成 GraphQL》:http://garymeng.com/2876.html。
4.2 一些约束
在开始前,先厘清一些基础的观念:
- 至少提供
first或last其中一个参数在查询之中,不建议同时提供两个参数进行查询,这容易造成资料排序的混淆。 - 下一页(Next Page):需要透过
first + after这两个参数作为搭配,其中first需要为正整数,而after是接受一个cursor type的参数并使用最后一个edge的cursor来作为after。 - 上一页(Previous Page):需要透过
last + before这两个参数作为搭配,其中last需要为正整数,而before是接受一个cursor type的参数并使用第一个edge的cursor来作为before。
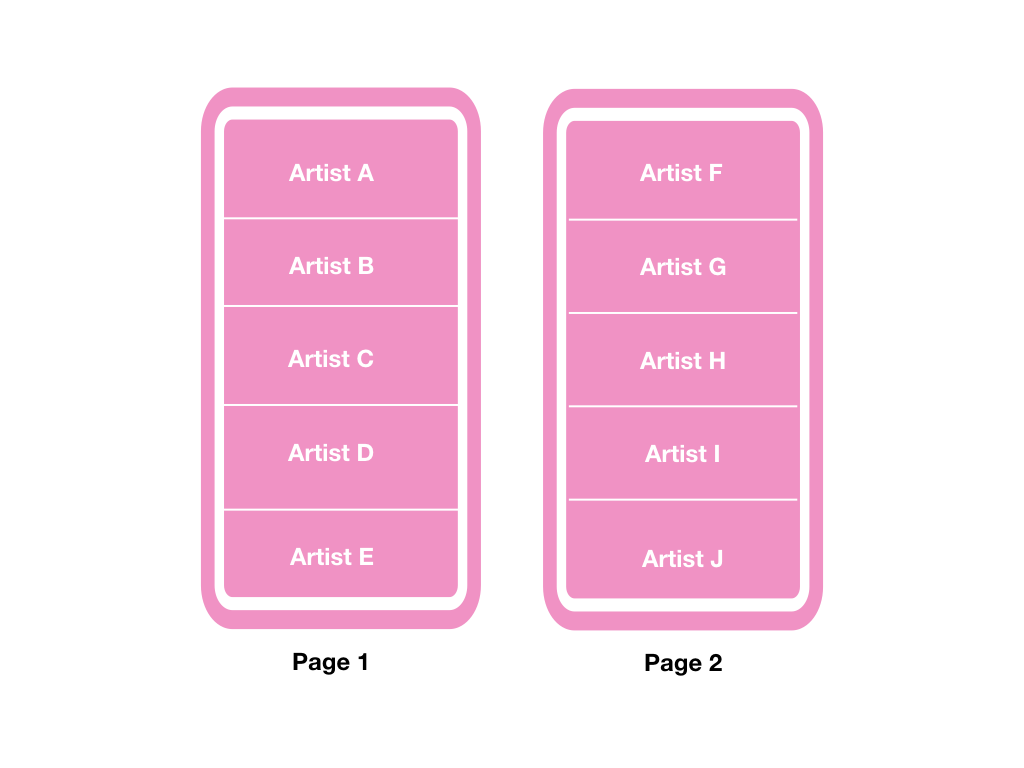
以上图为例,一开始取得第一页资料的时候会是:
{
artists(first : 5) {
edges {
node {
name
}
cursor
}
pageInfo {
hasNextPage
hasPreviousPage
endCursor
}
}
}
若要取得第二页就必须透过Artist E 的cursor:
{
artists(first: 5, cursor: $artistECursor) {
edges {
node {
name
}
cursor
}
pageInfo {
hasNextPage
hasPreviousPage
endCursor
}
}
}
首先,在每次查询的时候,至少都要提供first或last其中一个参数,作为你要取得资料的笔数,而官方不建议同时提供first以及last参数,因为它会造成导致混乱的查询结果,当然它们所搭配的参数after和before,也要避免同时存在。
所以在查询时,先检查这些相关的参数,并给予对应的错误处理或回应,这部分可在实际代码中处理,本文不作体现。
4.3 schema文件
首先,我们要定义出完整的 Schema 文件:
type Query {
artists(first: Int, after: String, last: Int, before: String): ArtistsConnection
}
type Artist {
id: String!
name: String!
}
type ArtistsConnection {
edges: [ArtistEdge!]!
pageInfo: PageInfo!
}
type ArtistEdge {
node: Artist!
cursor: String!
}
type PageInfo {
hasNextPage: Boolean!
hasPreviousPage: Boolean!
}
4.4 Java实现
实现细节如下,文件:src/main/java/org/termi/community/resolver/Query.java,具体内容如下:
package org.termi.community.resolver;
import graphql.kickstart.tools.GraphQLQueryResolver;
import graphql.relay.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.termi.community.model.Artist;
import org.termi.community.service.artist.ArtistService;
import org.termi.community.util.CursorUtil;
import java.util.List;
import java.util.stream.Collectors;
@Component
public class Query implements GraphQLQueryResolver {
@Autowired
private ArtistService artistService;
public Connection<Artist> getArtists(int first, String after) {
// 从after中解析出最后一条数据的ID
Long lastId = 0L;
if (after != null) {
lastId = CursorUtil.decode(after);
}
// 这一条相当于 select * from artist where id > $lastId limit ($first + 1)
// 比 first 多取一条数据,用于判断是否还有下一页
List<Artist> artists = artistService.selectAlls(first + 1, lastId);
// 是否还有下一页
boolean hasNextPage = artists.size() > first;
// 如果有下一页,则删除最后那一条冗余的数据
if (hasNextPage) {
artists.remove(artists.size() - 1);
}
// 把数据塞到Edges里面
List<Edge<Artist>> edges = artists
.stream()
.map(artist -> new DefaultEdge<>(artist, CursorUtil.encode(artist.getId())))
.collect(Collectors.toList());
// 分页信息
PageInfo pageInfo = new DefaultPageInfo(
CursorUtil.getStartCursorFrom(edges),
CursorUtil.getEndCursorFrom(edges),
false,
hasNextPage
);
// 返回 Connection
return new DefaultConnection<>(edges, pageInfo);
}
}
其中 CursorUtil 主要是用于加解密游标的,所在文件:src/main/java/org/termi/community/util/CursorUtil.java,内容:
package org.termi.community.util;
import graphql.relay.ConnectionCursor;
import graphql.relay.DefaultConnectionCursor;
import graphql.relay.Edge;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.List;
public class CursorUtil {
public static ConnectionCursor encode(Long id) {
return new DefaultConnectionCursor(
Base64.getEncoder().encodeToString(id.toString().getBytes(StandardCharsets.UTF_8))
);
}
public static Long decode(String cursor) {
return Long.parseLong(new String(Base64.getDecoder().decode(cursor)));
}
public static <T> ConnectionCursor getStartCursorFrom(List<Edge<T>> edges) {
return edges.isEmpty() ? null : edges.get(0).getCursor();
}
public static <T> ConnectionCursor getEndCursorFrom(List<Edge<T>> edges) {
return edges.isEmpty() ? null : edges.get(edges.size() - 1).getCursor();
}
}
5 测试
访问 http://localhost:8080/playground,查询:
{
artists(first: 5) {
edges {
node {
id
name
}
cursor
}
pageInfo {
hasNextPage
hasPreviousPage
startCursor
endCursor
}
}
}
参考资料:
博主有心人